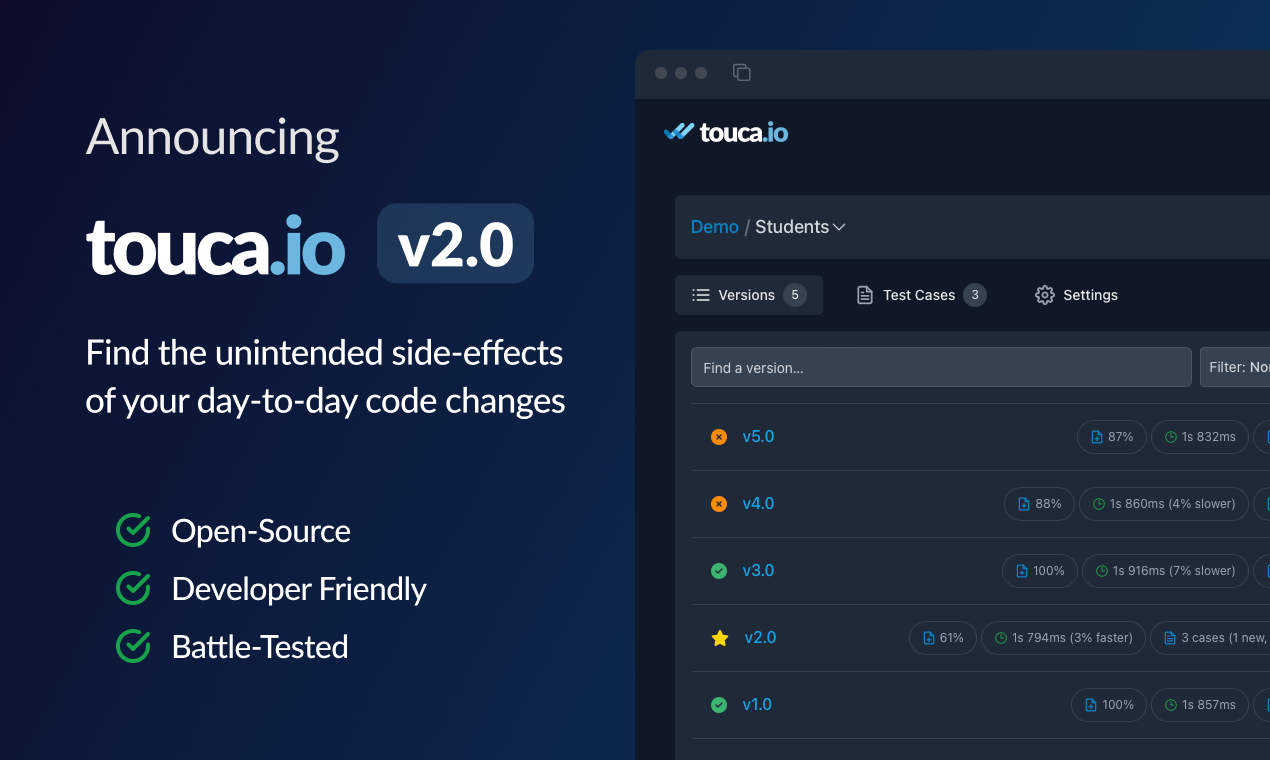
Like any other software component, machine learning models evolve over time. Data teams frequently make changes to their models to adjust and improve their effectiveness in meeting business needs. Understanding the true impact of these changes is essential but non-trivial.
Software engineering teams rely on a variety of testing tools and techniques to continuously validate their code changes. But these tools are not equally accessible or relevant to data teams. The common reasoning is that describing the expected outcome of machine learning models is more difficult than that of other software workflows. While this is true, part of the difficulty stems from trying to describe the behavior of these models in such ways to fit the requirements of established testing techniques like integration testing.
Touca, as an open-source regression testing system, is well positioned to address this difficulty and to effectively solve the testing needs of most data teams. This article showcases how Touca can help identify and evaluate changes in the behavior of a simple classification algorithm.
The Problem
Let's assume we have a database of cancerous and non-cancerous tumors. The cancerous tumors fall into 3 categories depending on the progress of the disease. These "stages" range from 1 (the most nascent) to 3 (the most advanced). A particular treatment is available for patients with stage 3 tumors that is only advisable for this stage of the disease and could significantly reduce the chance of success if tried in the earlier stages.
We would like to build a machine learning model that correctly diagnoses the stage of disease for each patient. As data scientists we may have many ideas on how to approach this problem. It is common that we would start with one potential model and then use it as a baseline to evaluate future models.
In the following sections, we will go through this process step by step and present two potential models for this problem. We will highlight how we can use Touca to describe each model and to see how they compare against each other.
Generating Synthetic Data
In real-world, we would have the data provided to us. Perhaps we will even have a clinically verified validation dataset reserved for evaluating and monitoring the performance of our models. In this example, in the absence of that data, we could use synthetic data instead. One very straightforward way of doing so is using scikit's make_classification method:
from sklearn.datasets import make_classification
x, y = make_classification(
n_samples=1000,
n_classes=4,
n_features=10,
class_sep=5,
n_redundant=0,
n_informative=4,
random_state=0,
)
We specify the number of samples n_samples, the number of classes n_classes (0 for non-cancerous cases and 1 to 3 for different stages of cancerous cases), the number of features n_features including the number of redundant (n_redundant) and informative (n_informative) features, and a random seed random_state for replicability. In addition, we use class_sep to control the spread of classes and hence the easiness of classification, with larger values making the task easier.
Side Note: We are ignoring potential class imbalance issues here for simplicity: In the real-world, the number of stage-3 cases would be much smaller than other cases. Achieving a distribution similar to real-world datasets would require a few extra steps that are beyond the scope of this blog post.
Model 1: A Logistic Regression with Four Labels
Our first idea is to fit a logistic regression model to classify the records into their four categories. We can start by splitting the data into training and test data. We would standardize the features and fit our model:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
pipeline = Pipeline([('scaler', StandardScaler()), ('LR', LogisticRegression())])
pipeline.fit(x_train, y_train)
Among other metrics, perhaps most importantly, we could review the performance of our model on stage-3 cases.
from sklearn.metrics import accuracy_score
stage_3_x_test = x_test[y_test == 3]
stage_3_y_test = y_test[y_test == 3]
stage_3_accuracy_score = accuracy_score(
y_true=stage_3_y_test,
y_pred=pipeline.predict(stage_3_x_test),
normalize=True
)
print(f"The accuracy score of predicting stage 3 cases: {stage_3_accuracy_score.round(4)}")
Assuming we are happy with this performance, we may want to store our machine learning pipeline for deployment.
from pathlib import Path
import joblib
data_dir = Path("data")
data_dir.mkdir(exist_ok=True)
joblib.dump(pipeline, data_dir.joinpath("pipeline.bin"))
We can also store our test cases so we can use them to validate future versions of our model.
testcase_dir = data_dir.joinpath("testcases")
testcase_dir.mkdir(parents=True, exist_ok=True)
# store the numerical data for each case in a separate binary file
for idx, input in enumerate(stage_3_x_test):
filepath = testcase_dir.joinpath(f"testcase-{idx}").with_suffix(".bin")
input.tofile(filepath)
# store the list of all test cases in `testcases.txt`
testcases = [x.stem for x in testcase_dir.glob("*.bin")]
testcases.sort()
data_dir.joinpath("testcases.txt").write_text("\n".join(testcases))
You can run the steps above via running python src/model_v1.py in the example directory.But how do we capture how our current model performs on these cases? How could we detect and describe how future versions perform in comparison with our current model? While there is no one-size-fits-all answer for these questions, Touca is particularly effective for describing the behavior of complex software workflows for a large variety of input data.
Establishing our baseline
Touca provides SDKs that help us submit the behavioral characteristics of our model to a remote Touca Server instance. In this example, we can submit the predicted outcome of our current model for each testcase. The server retains this information for each version of our model and automatically compares each version against a baseline version and visualizes any differences in near real-time.
Let's use Touca's Python SDK to write our first Touca test:
import touca
import joblib
import numpy as np
# Load machine learning model from file
pipeline = joblib.load("data/pipeline.bin")
@touca.Workflow
def pipeline_test(testcase: str):
# for each test case, load input data from a corresponding binary file
testcase_input = np.fromfile(f"data/testcases/{testcase}.bin", dtype=float)
# perform prediction on the input data
outcome = pipeline.predict([testcase_input])[0]
# submit the predicted classification to the Touca server
touca.check("stage", outcome.item())
pip install touca --quiet
touca config set api-key=<TOUCA_API_KEY>
touca config set api-url=<TOUCA_API_URL>
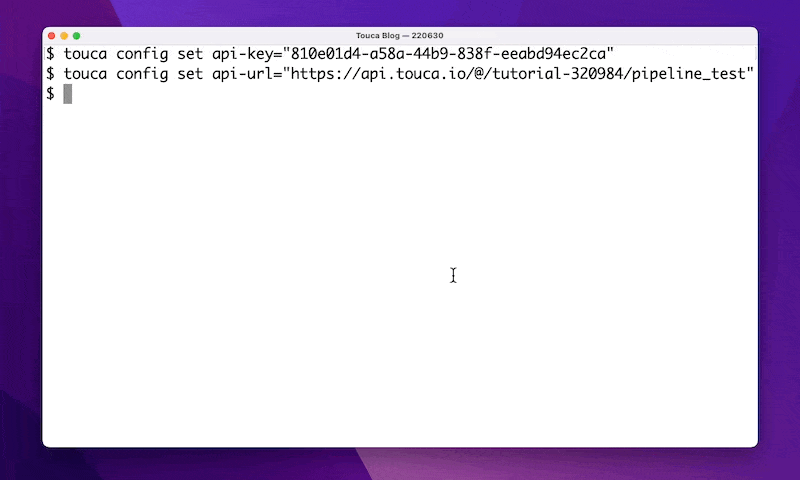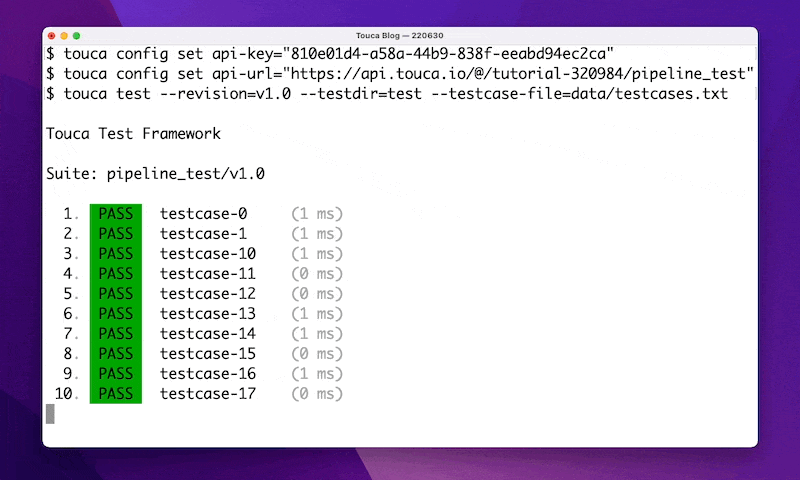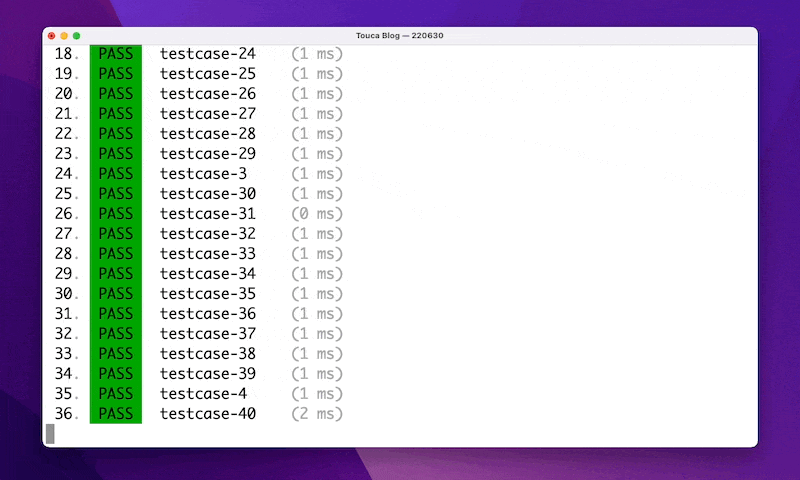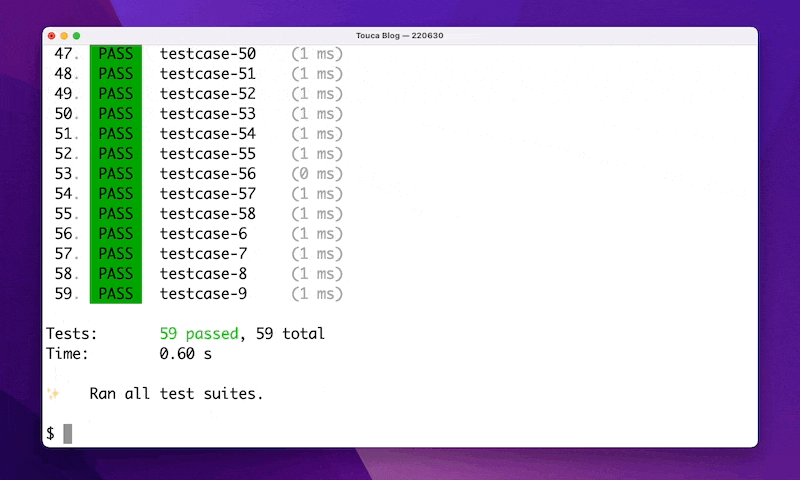
touca test --revision=v1.0 --testdir=test --testcase-file=data/testcases.txt
Where the options api_key and api-url are obtained from the Touca Server, self-hosted locally or deployed in the Cloud, revision is any string representation of the version of our code under test, and testcase_file points to a list of our testcases.
Checkout our documentation website for instructions to create an account and obtain your API credentials.
The Touca test above, takes a list of testcase names as input, and passes each testcase name to our pipeline_test function. For each test case, we load our input data from a corresponding binary file, run our machine learning model against it, and submit the predicted classification to the Touca server.
Unlike unit tests and integration tests, Touca tests do not use any assertion or expected values. The submitted test results are compared remotely against the submitted test results for a previous trusted version.
Model 2: A Logistic Regression with Two Labels: Stage-3 vs. Other
Now that we have deployed our first model and have a baseline of how it performs on our test cases, we can proceed with exploring other ideas on how to approach our classification problem:
If we particularly care about detecting stage-3 cases, wouldn't it make sense to use binary classification instead? Our model could flag stage-3 cases against all other cases of non-cancerous and nascent cases. It is tempting to consider this model with the argument that it may be potential faster and more effective than our previous 4-label classification model.
import numpy as np
y_train_binary_class = np.array([c if c == 3 else -1 for c in y_train])
y_test_binary_class = np.array([c if c == 3 else -1 for c in y_test])
pipeline = Pipeline([('scaler', StandardScaler()), ('LR', LogisticRegression())])
pipeline.fit(x_train, y_train_binary_class)
Assuming we are happy with the implementation, we can now store this new model locally or as part of CI, to evaluate it against our previous baseline. Depending on this evaluation, we can then choose whether to proceed with deploying this new version to production.
joblib.dump(pipeline, "data/pipeline.bin")
You can run the steps above via running python src/model_v2.py in the example directory.Comparing against baseline
Fortunately, with Touca, we can reuse our previous test to submit the new behavior to the server and let it compare our the behavior against our baseline.
touca test --revision=v2.0 --testdir=test
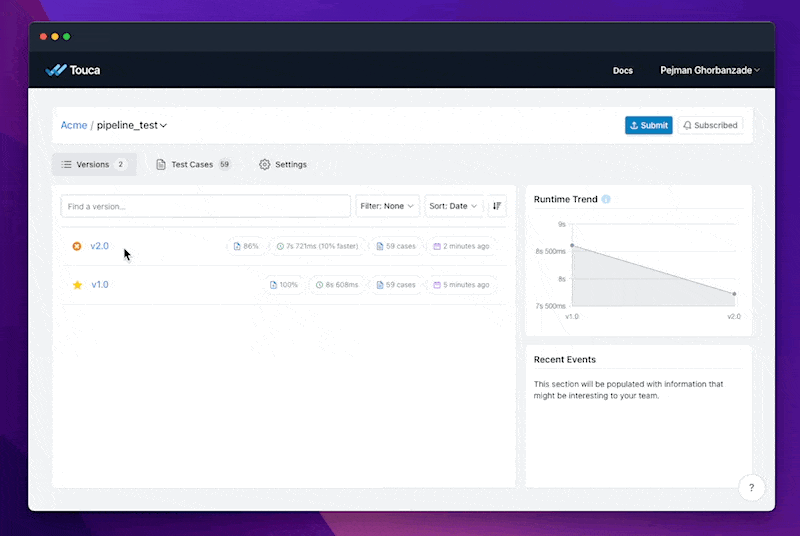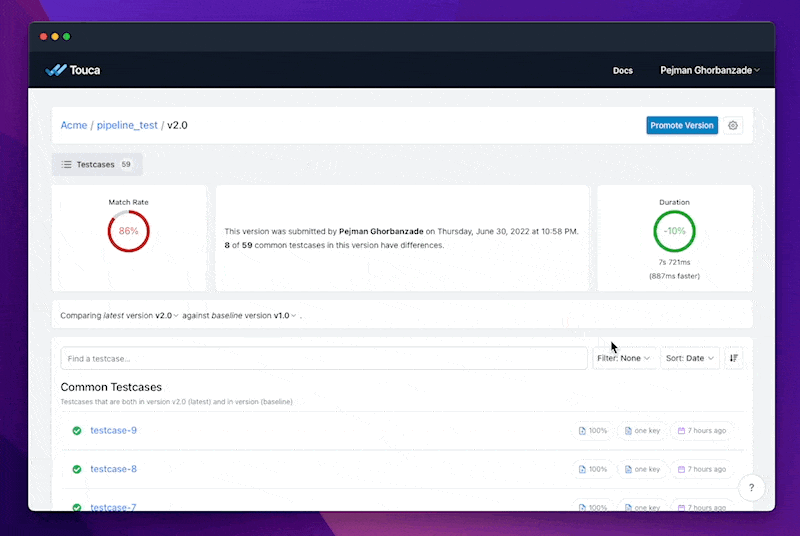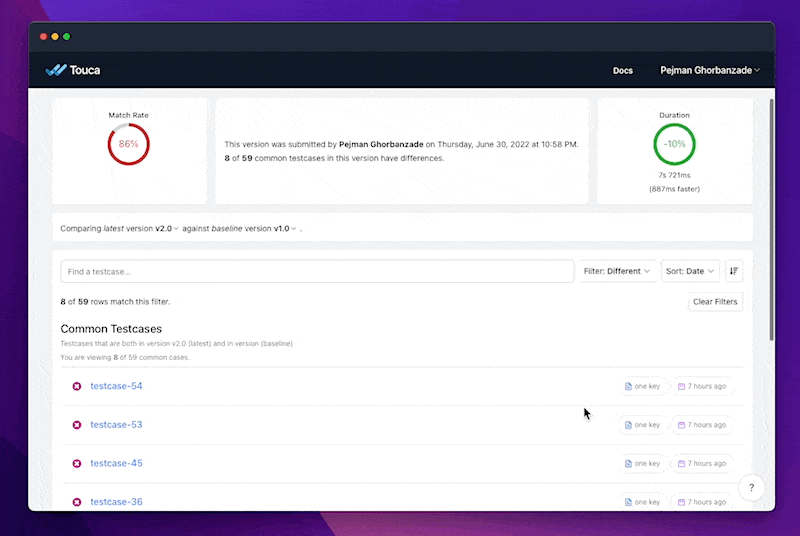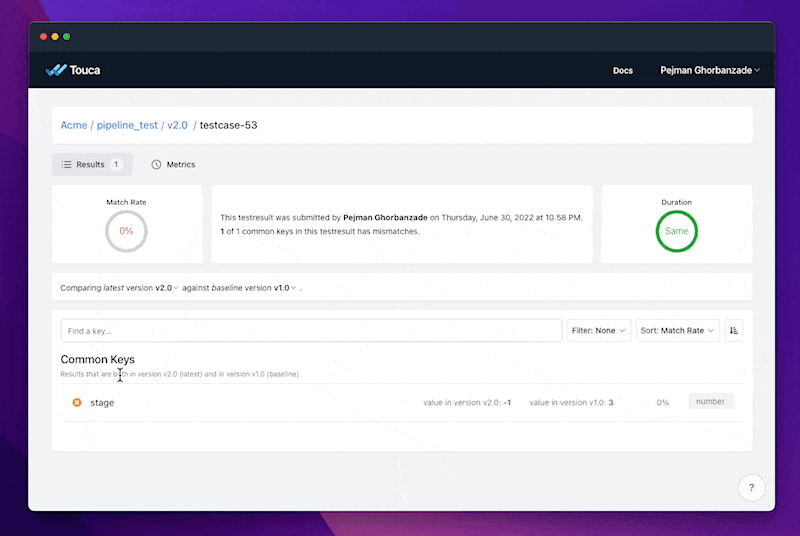
In this example, we can see that the new model misdiagnoses several stage-3 test cases. While this finding is not evidence by itself that our new model is worse, it can help data teams better understand the implications of deploying it to production, especially if there are business requirements such as policies and regulation that dictate that the model should behave a certain way for our list of testcases.
Side Note: It may be surprising to see that a binary classification model is performing worse than our original model. This behavior could be attributed to the large number of stage-3 cases in our dataset which could be mitigated via adding a balancing step that is beyond the scope of this post. Since we now have an established baseline, Touca could be very effective in investigating and evaluating these future changes.
We submitted a single data-point here which was sufficient for our use-case. In real-world where software workflows are more complex, we can submit a large number of data points with arbitrary data types to fully capture the behavior and performance of our software for a variety of test cases.
Retaining all our test results on the Touca server lets us delegate the comparison and processing of test results to Touca, fully automating visualization and reporting of differences. The server also enables shared access to the test results among members of our team, serving as a collaborative platform for inspecting and managing how our software evolves over time.
Thank you to Mihai Maruseac, Vahid Behzadan, and Elham Khoshfam for reviewing early drafts of this blog post.